
皆さん、こんにちは!本日は、ウェブブラウザの操作を自動化するツール「BrowserUse」についてご紹介します。
インターネットが日常生活に欠かせない現代において、ウェブブラウザを通じた情報のやり取りはますます重要になっていますね。しかし、繰り返し行う作業や大量のデータ処理は、時間も労力もかかり、大変な作業です。そこで注目されているのが、ウェブブラウザ操作の「自動化」です。
自動化によって、これまで手作業で行っていた面倒なタスクを効率化し、時間とコストを削減できます。そんな自動化を強力にサポートするのが、今回紹介する「BrowserUse」です。
BrowserUseって何?

https://github.com/browser-use/browser-use
BrowserUseは、ウェブブラウザの操作を自動化するためのツールです。主にPythonで実装されており、簡単にブラウザ操作を自動化するスクリプトを作成できます。
特に注目すべきは、LLM(大規模言語モデル)との連携機能です。ChatGPTなどのLLMを活用することで、より高度で柔軟な自動化を実現しています。
BrowserUseの主な特徴は?
LLMとの連携で、もっと賢く!
BrowserUseの最大の特徴は、ChatGPTなどのLLMと連携できることです。これにより、自然言語での指示に基づいて、ブラウザ操作を実行できます。例えば、「〇〇のサイトで最新ニュースを検索して」といった指示を理解し、実行できるのです。
カスタムアクションで、自由にカスタマイズ!
BrowserUseでは、ユーザーが任意の操作を追加できる「カスタムアクション」機能が提供されています。これにより、特定のウェブサイトやアプリケーションに特化した、独自の自動化処理を組み込むことが可能です。
並列処理で、効率アップ!
複数のブラウザ操作を同時に実行できる「並列処理」にも対応しています。これにより、大量のデータ収集や処理を、効率的に行うことができます。
BrowserUseはどんなシーンで活躍するの?
BrowserUseは、様々なシーンで活用できます。
ウェブデータの収集・解析を自動化!
例えば、特定のウェブサイトから定期的に情報を収集し、分析する作業を自動化できます。これにより、市場調査や競合分析などの業務を効率化できます。
面倒なフォーム入力やレポート作成も楽々!
大量のフォーム入力や、定型的なレポート作成も、BrowserUseで自動化できます。これにより、時間と労力を大幅に削減し、人的ミスも減らすことができます。
ユーザー体験向上のためのシステム統合にも!
ウェブアプリケーションのテスト自動化や、複数のウェブサービスを連携させるシステム統合などにも活用できます。これにより、ユーザー体験の向上や、業務プロセスの効率化に貢献できます。
BrowserUseの環境構築手順
BrowserUseを使うには、Pythonの環境といくつかのライブラリが必要です。ここでは、環境構築の手順を説明します。
1. Pythonのインストール
まず、お使いのPCにPythonがインストールされているか確認しましょう。ターミナル(またはコマンドプロンプト)を開き、以下のコマンドを実行してください。
python --versionPythonのバージョンが表示されれば、インストールされています。もし、command not found などのエラーが出る場合は、Pythonがインストールされていませんので、インストールしましょう。
Pythonの公式サイト(https://www.python.org/)から、お使いのOSに合ったインストーラーをダウンロードし、実行してください。
2. 必要なライブラリのインストール
BrowserUseを使用するには、以下のライブラリが必要です。
- browser-use: BrowserUseの本体
- playwright: ブラウザ操作を自動化するためのライブラリ
- langchain-openai: 大規模言語モデルと連携するためのライブラリ(オプション)
これらのライブラリは、pipコマンドを使ってインストールできます。ターミナルで以下のコマンドを実行してください。
pip install browser-use次に、Playwrightをインストールするために、以下のコマンドを実行します。
playwright installLLMとの連携機能(オプション)を使用する場合は、さらに以下のコマンドを実行して、langchain-openaiをインストールしてください。
pip install langchain-openai3. APIキーの設定(LLM連携を行う場合)
LLM(例:OpenAIのChatGPT)との連携機能を使う場合は、APIキーの設定が必要です。
まず、.env という名前のファイルを作成し、以下の内容を書き込んでください。
OPENAI_API_KEY=ここにあなたのAPIキーを入力ここにあなたのAPIキーを入力 の部分を、OpenAIから取得したAPIキーに置き換えてください。
4. (オプション) 動作確認
以下のコマンドで、BrowserUseが正しくインストールされ、動作することを確認できます。
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="Go to Reddit, search for 'browser-use' in the search bar, click on the first post and return the first comment.",
llm=ChatOpenAI(model="gpt-4o"),
)
result = await agent.run()
print(result)
asyncio.run(main())このコードは、browser-useのGitHubリポジトリに記載されている動作確認用のコードです。もしエラーが発生しなければ、無事に環境構築は完了しています。
BrowserUseを使ってみよう!実装例を紹介
環境構築が完了したら、いよいよBrowserUseを使ってみましょう!
import asyncio
import os
from browser_use import Agent, Controller, Browser, BrowserConfig
from browser_use.browser.context import BrowserContext
from langchain_openai import ChatOpenAI
# Controller を初期化
controller = Controller()
@controller.registry.action('take_screenshot', requires_browser=True)
async def take_screenshot(browser: BrowserContext, path: str = "screenshot.png"):
"""
現在のタブのスクリーンショットを撮るアクション。
"""
# フォルダが存在しない場合は作成
os.makedirs("screenshot", exist_ok=True)
page = await browser.get_current_page()
screenshot_path = os.path.join("screenshot", path)
await page.screenshot(path=screenshot_path)
print(f"スクリーンショットを {screenshot_path} に保存しました。")
return {
"extracted_content": f"{screenshot_path} に保存完了",
"include_in_memory": True
}
async def main():
# ブラウザの設定(例として headless=False, keep_open=True)
browser = Browser(
config=BrowserConfig(
headless=False,
# keep_open=True,
)
)
# タスク例
target_url = "https://moji.onl.jp/"
task = f"指定されたURL '{target_url}' にアクセスし、入力欄に「あいうえお」と入力し、文字数のボタンを押してください。また、その結果をスクリーンショットで保存してください。画像の名前は、'moji_result.png'としてください。"
# LLMのセットアップ
model = ChatOpenAI(model='gpt-4o')
# Agent に controller を渡す(controller に定義したアクションが呼び出されます)
agent = Agent(
task=task,
llm=model,
browser=browser,
controller=controller,
)
await agent.run()
await browser.close()
if __name__ == "__main__":
asyncio.run(main())このサンプルコードでは、指定されたウェブサイト(https://moji.onl.jp/)にアクセスし、「あいうえお」と入力欄に入力して文字数カウントボタンを押し、結果をスクリーンショットに保存するという一連のタスクをAgentに実行させています。
このように、BrowserUseを使えば、ウェブサイトへのアクセス、フォームへの入力、ボタンのクリック、結果の取得といった一連の流れを簡単に自動化できることがわかります。
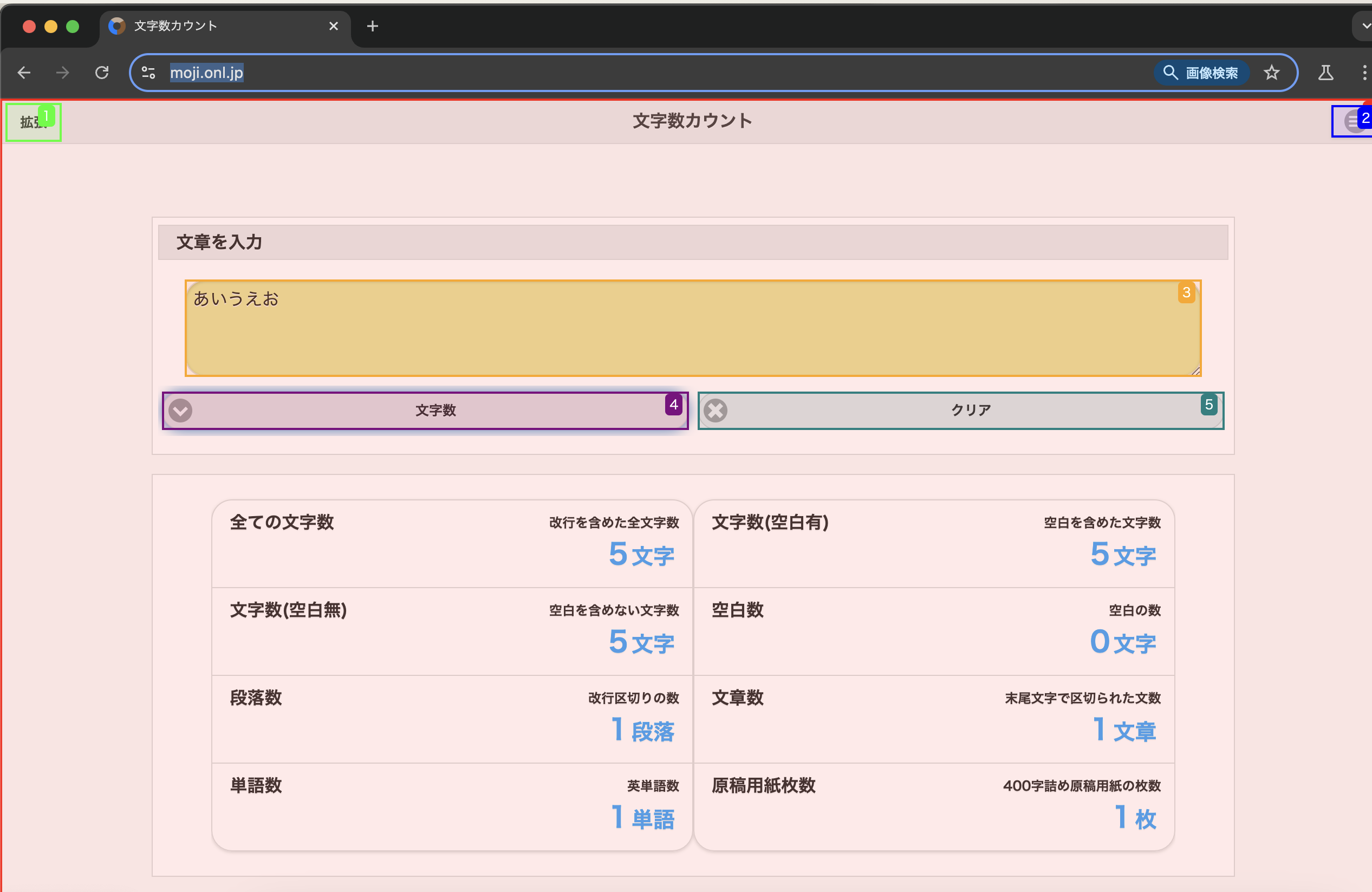
下記画像のようにブラウザが自動で立ち上がり、ブラウザ上のボタン配置等を分析しているのがわかります!すごいですね!
実際に入力欄に「あいうえお」と入力し、「文字数」ボタンを押下し、文字数を計測してくれました。
BrowserUseの利点と課題は?
BrowserUseは非常に便利なツールですが、利点だけでなく課題もあります。
利点:作業効率の向上と人的ミスの削減!
BrowserUseの最大の利点は、作業効率を大幅に向上させることができる点です。また、自動化によって人的ミスを削減し、作業の正確性を高めることもできます。
課題:セキュリティリスクと信頼性の確保
一方で、自動化にはセキュリティリスクが伴うことも事実です。また、ウェブサイトの仕様変更などにより、自動化スクリプトが正常に動作しなくなる可能性もあります。そのため、セキュリティ対策を徹底し、定期的なメンテナンスを行うことが重要です。
BrowserUseを使う上での注意点
BrowserUseを利用する際には、以下の点に注意する必要があります。
プライバシーとセキュリティへの配慮
自動化を行う際には、プライバシーとセキュリティに十分配慮する必要があります。個人情報や機密情報の取り扱いには、特に注意が必要です。
まとめと今後の展望
BrowserUseは、ウェブブラウザ操作を自動化し、作業効率を大幅に向上させることができる強力なツールです。LLMとの連携により、今後さらに高度な自動化が可能になると期待されています。
BrowserUseを活用して、日々の業務を効率化し、より創造的な仕事に時間を費やしてみてはいかがでしょうか。
今後も、BrowserUseのさらなる発展と、様々な分野での応用が期待されます。BrowserUseの進化に、ぜひ注目していきましょう!